В прошлой статье я говорил, что Prometheus — это не готовое решение, а скорее фреймворк. Чтобы использовать его возможности полноценно, надо разбираться. Что ж, начнём.
PromQL — это про то, как вытаскивать метрики не из экспортеров, а уже из самого Prometheus’а. Например, чтобы узнать сколько ядер у процессора, надо написать:
count(count(node_cpu_seconds_total) without (mode)) without (cpu)
PromQL дословно расшифровывается как Prometheus query language, т.е. язык запросов. Он не имеет ничего общего с SQL, это принципиально другой язык. Поначалу он казался мне каким-то запутанным, а документация не особо помогала. Потихоньку разобрался и мне даже понравилось.
- Пробуем простые запросы
- Агрегация
- Считаем ядра процессора
- Мгновенный и диапазонный вектор
- Типы метрик
- Смотрим счётчики
Пробуем простые запросы
Prometheus server хранит все данные в виде временных последовательностей (time series). Каждая временная последовательность определяется именем метрики и набором меток (labels) типа ключ-значение (key-value). Давайте сразу посмотрим несколько примеров в Prometheus web UI. Напомню, он работает на localhost:9090. Чтобы не городить скриншотов, я буду показывать запросы в своём псевдо-терминале, а вы не ленитесь и пробуйте у себя.
Expression: node_load1
0.96node_load1{instance="localhost:9100",job="node"}
node_load1 — имя метрики,
instance и job — имена меток,
localhost:9100 и node — соответствующие значения меток,
0.96 — значение метрики.
Можно запустить какой-нибудь top и убедиться в том, что одноминутный load average на локалхосте действительно равен 0.96.
Если у вас несколько машин, результат будет интереснее:
Expression: node_load1
0.96node_load1{instance="localhost:9100",job="node"}
0.44node_load1{instance="anotherhost:9100",job="node"}
Prometheus разрабатывался так, чтобы наблюдать за группой машин было так же легко, как за одной. И метки этому способствуют. Прежде всего они позволяют фильтровать вывод:
Expression: node_load1{instance='localhost:9100'}
0.96node_load1{instance="localhost:9100",job="node"}
Expression: node_load1{instance!='localhost:9100'}
0.44node_load1{instance="anotherhost:9100",job="node"}
Expression: node_load1{job='node'}
0.96node_load1{instance="localhost:9100",job="node"}
0.44node_load1{instance="anotherhost:9100",job="node"}
Кроме = и != есть ещё совпадение и несовпадение с регулярным выражением: =~, !~. Лирическое отступление: мне не нравится одинарное равно для точного сопадения. Это против правил. Должно быть двойное! Эх, молодёжь… А вот разницы в кавычках я не заметил: одинарные и двойные работают одинаково. Да, если задать несколько условий, они будут объединяться логическим И.
Возьмём другой пример. Посмотрим свободное место на дисках:
Expression: node_filesystem_avail_bytes
node_filesystem_avail_bytes{device="/dev/nvme0n1p1",fstype="vfat",instance="localhost:9100",job="node",mountpoint="/boot"} 143187968
node_filesystem_avail_bytes{device="/dev/nvme0n1p2",fstype="ext4",instance="localhost:9100",job="node",mountpoint="/"} 340473708544
node_filesystem_avail_bytes{device="/dev/sda1",fstype="ext4",instance="anotherhost:9100",job="node",mountpoint="/"} 429984710656
node_filesystem_avail_bytes{device="run",fstype="tmpfs",instance="localhost:9100",job="node",mountpoint="/run"} 4120506368
node_filesystem_avail_bytes{device="tmpfs",fstype="tmpfs",instance="localhost:9100",job="node",mountpoint="/tmp"} 4109291520
node_filesystem_avail_bytes{device="tmpfs",fstype="tmpfs",instance="anotherhost:9100",job="node",mountpoint="/run"} 104542208
В байтах получаются огромные непонятные числа, но сейчас не обращайте на это внимания — мы упражняемся в запросах.
Можно получить свободное место в процентах:
Expression: node_filesystem_avail_bytes / node_filesystem_size_bytes * 100
{device="/dev/nvme0n1p1",fstype="vfat",instance="localhost:9100",job="node",mountpoint="/boot"} 54.17850016466805
{device="/dev/nvme0n1p2",fstype="ext4",instance="localhost:9100",job="node",mountpoint="/"} 73.94176693455515
{device="/dev/sda1",fstype="ext4",instance="anotherhost:9100",job="node",mountpoint="/"} 68.54660550632083
{device="run",fstype="tmpfs",instance="localhost:9100",job="node",mountpoint="/run"} 99.96800174897272
{device="tmpfs",fstype="tmpfs",instance="localhost:9100",job="node",mountpoint="/tmp"} 99.69591724179051
{device="tmpfs",fstype="tmpfs",instance="anotherhost:9100",job="node",mountpoint="/run"} 99.83961821311219
tmpfs — это не про диск, уберём его:
Expression: node_filesystem_avail_bytes{fstype!='tmpfs'} / node_filesystem_size_bytes{fstype!='tmpfs'} * 100
{device="/dev/nvme0n1p1",fstype="vfat",instance="localhost:9100",job="node",mountpoint="/boot"} 54.17850016466805
{device="/dev/nvme0n1p2",fstype="ext4",instance="localhost:9100",job="node",mountpoint="/"} 73.94172957355208
{device="/dev/sda1",fstype="ext4",instance="anotherhost:9100",job="node",mountpoint="/"} 68.5466042003818
Не обязательно указывать одинаковый фильтр для всех операндов, как я только что сделал. Достаточно одного, а дальше Prometheus сам возьмёт пересечение по меткам. Следовательно, последний запрос можно с чистой совестью сократить до такого:
Expression: node_filesystem_avail_bytes{fstype!='tmpfs'} / node_filesystem_size_bytes * 100
или
Expression: node_filesystem_avail_bytes / node_filesystem_size_bytes{fstype!='tmpfs'} * 100
Мы получили свободное место в процентах, но как-то привычнее другая величина — занятое место в процентах:
Expression: 100 - node_filesystem_avail_bytes{fstype!='tmpfs'} / node_filesystem_size_bytes * 100
или
Expression: (1 - node_filesystem_avail_bytes{fstype!='tmpfs'} / node_filesystem_size_bytes) * 100
{device="/dev/nvme0n1p1",fstype="vfat",instance="localhost:9100",job="node",mountpoint="/boot"} 45.82149983533195
{device="/dev/nvme0n1p2",fstype="ext4",instance="localhost:9100",job="node",mountpoint="/"} 26.05827042644792
{device="/dev/sda1",fstype="ext4",instance="anotherhost:9100",job="node",mountpoint="/"} 31.453395799618207
Как видите, можно умножать или делить на скаляр и не важно что это: константа или результат вычисления. Вообще я заметил, что в PromQL действует правило: пиши осмысленные запросы и всё будет хорошо. Не надо пытаться сложить диск с процессором и делить на память.
Агрегация
По меткам можно делать агрегацию. Смысл агрегации в том, чтобы объединить несколько однотипных метрик в одну. Например, посчитать максимальный (или средний) load average среди машин определённой группы.
Expression: foo by (label) (some_metric_name)
или
Expression: foo(some_metric_name) by (label)
Синтаксис непривычный, но вроде ничего. Все эти скобочки являются обязательными, без них работать не будет. Пробуем на нашем load average:
Expression: avg by (job)(node_load1)
0.7{job="node"}
Expression: max by (job)(node_load1)
0.96{job="node"}
Expression: min by (job)(node_load1)
0.44{job="node"}
Expression: sum by (job)(node_load1)
1.4{job="node"}
Expression: count by (job)(node_load1)
2{job="node"}
Метки работают как измерения в многомерном пространстве. Агрегация с использованием by как бы схлопывает все измерения, кроме указанного. В примере с node_load1 это не очень заметно, потому что у меня мало меток и хостов. Ок, вот пример получше:
Expression: node_cpu_seconds_total
27687.16node_cpu_seconds_total{cpu="0",instance="localhost:9100",job="node",mode="idle"}
349.98node_cpu_seconds_total{cpu="0",instance="localhost:9100",job="node",mode="iowait"}
0node_cpu_seconds_total{cpu="0",instance="localhost:9100",job="node",mode="irq"}
4.5node_cpu_seconds_total{cpu="0",instance="localhost:9100",job="node",mode="nice"}
342.47node_cpu_seconds_total{cpu="0",instance="localhost:9100",job="node",mode="softirq"}
0node_cpu_seconds_total{cpu="0",instance="localhost:9100",job="node",mode="steal"}
734.43node_cpu_seconds_total{cpu="0",instance="localhost:9100",job="node",mode="system"}
2386.23node_cpu_seconds_total{cpu="0",instance="localhost:9100",job="node",mode="user"}
27613.56node_cpu_seconds_total{cpu="1",instance="localhost:9100",job="node",mode="idle"}
328.26node_cpu_seconds_total{cpu="1",instance="localhost:9100",job="node",mode="iowait"}
...
Эта метрика показывает сколько времени каждое ядро работало в каждом режиме. В сыром виде от неё никакого толку, но сейчас это не важно. Важно, что у неё куча меток: cpu, instance, job, mode.
Expression: max by (instance) (node_cpu_seconds_total)
18309.45{instance="localhost:9100"}
3655352.98{instance="anotherhost:9100"}
Expression: max by (instance, cpu) (node_cpu_seconds_total)
17623.34{cpu="3",instance="localhost:9100"}
18295.97{cpu="0",instance="localhost:9100"}
3529407.76{cpu="0",instance="anotherhost:9100"}
18252.21{cpu="1",instance="localhost:9100"}
3655379.15{cpu="1",instance="anotherhost:9100"}
18334{cpu="2",instance="localhost:9100"}
Expression: max without (mode) (node_cpu_seconds_total)
3655736.46{cpu="1",instance="anotherhost:9100",job="node"}
18752.74{cpu="2",instance="localhost:9100",job="node"}
18022.19{cpu="3",instance="localhost:9100",job="node"}
18716.18{cpu="0",instance="localhost:9100",job="node"}
3529779.38{cpu="0",instance="anotherhost:9100",job="node"}
18670.74{cpu="1",instance="localhost:9100",job="node"}
Оператор without работает как by, но в другую сторону, по принципу: “что получится, если убрать такую-то метку”. На практике лучше использовать именно without, а не by. Почему? Дело в том, что Prometheus позволяет навесить кастомных меток при объявлении таргетов, например разный env для машин тестового и боевого окружений (как это сделать). При составлении запроса вы заранее не знаете какие дополнительные метки есть у метрики и есть ли они вообще. А если и знаете, то не факт, что их число не изменится в будущем… В любом случае при использовании by все метки, которые не были явно перечислены, пропадут при агрегации. Это скорее всего будет некритично в дашбордах, но будет неприятностью в алертах. Так что лучше подумать дважды, прежде чем использовать by.
Попробуйте самостоятельно поиграться с агрегациями и понять как формируется результат. Полный список агрегирующих операторов вы найдёте в документации.
Считаем ядра
В принципе у вас уже достаточно знаний, чтобы самостоятельно посчитать ядра процессора, но я всё равно покажу. Для решения задачи нам нужна метрика node_cpu_seconds_total и оператор count, который показывает сколько значений схлопнулось при агрегации:
Expression: count(node_cpu_seconds_total) without (cpu)
4{instance="localhost:9100",job="node",mode="user"}
2{instance="anotherhost:9100",job="node",mode="iowait"}
2{instance="anotherhost:9100",job="node",mode="softirq"}
2{instance="anotherhost:9100",job="node",mode="system"}
2{instance="anotherhost:9100",job="node",mode="user"}
4{instance="localhost:9100",job="node",mode="system"}
2{instance="anotherhost:9100",job="node",mode="irq"}
4{instance="localhost:9100",job="node",mode="idle"}
4{instance="localhost:9100",job="node",mode="irq"}
4{instance="localhost:9100",job="node",mode="nice"}
4{instance="localhost:9100",job="node",mode="softirq"}
2{instance="anotherhost:9100",job="node",mode="nice"}
4{instance="localhost:9100",job="node",mode="iowait"}
2{instance="anotherhost:9100",job="node",mode="idle"}
2{instance="anotherhost:9100",job="node",mode="steal"}
4{instance="localhost:9100",job="node",mode="steal"}
Результат получился правильный, но хочется видеть лишь две строчки: одну для localhost и вторую для anotherhost. Для этого предварительно надо избавиться от метки mode любым из способов:
Expression: count(node_cpu_seconds_total) without (mode)
или
Expression: max(node_cpu_seconds_total) without (mode)
Итоговый запрос:
Expression: count(count(node_cpu_seconds_total) without (mode)) without (cpu)
4{instance="localhost:9100",job="node"}
2{instance="anotherhost:9100",job="node"}
Да, мне тоже кажется, что получение простой по смыслу метрики (число ядер) выглядит как-то заковыристо. Как будто мы ухо ногой чешем. Привыкайте.
Мгновенный и диапазонный вектор
Простите, я не смог придумать лучшего перевода. В оригинале это называется instant and range vector. Сейчас мы смотрели только мгновенные вектора, т.е. значения метрик в конкретный момент времени. Почему вообще результат запроса называется вектором? Вспоминаем, что Prometheus ориентирован на работу с группами машин, не с единичными машинами. Запросив какую-то метрику, в общем случае вы получите не одно значение, а несколько. Вот и получается вектор (с точки зрения алгебры, а не геометрии). Возможно, если погрузиться в исходный код Prometheus, всё окажется сложнее, но, к счастью, в этом нет необходимости.
Диапазонный вектор (range vector) — это вектор, который хранит диапазон значений метрики за определённый период времени. Он нужен, когда этого требует арифметика запроса. Проще всего объяснить на графике функции avg_over_time от чего-нибудь. В каждый момент времени она будет вычислять усреднённое значение метрики за предыдущие X минут (секунд, часов…). По-научному это называется “скользящее среднее” (moving average). На словах как-то сложно получается, лучше взгляните на эти 2 графика:
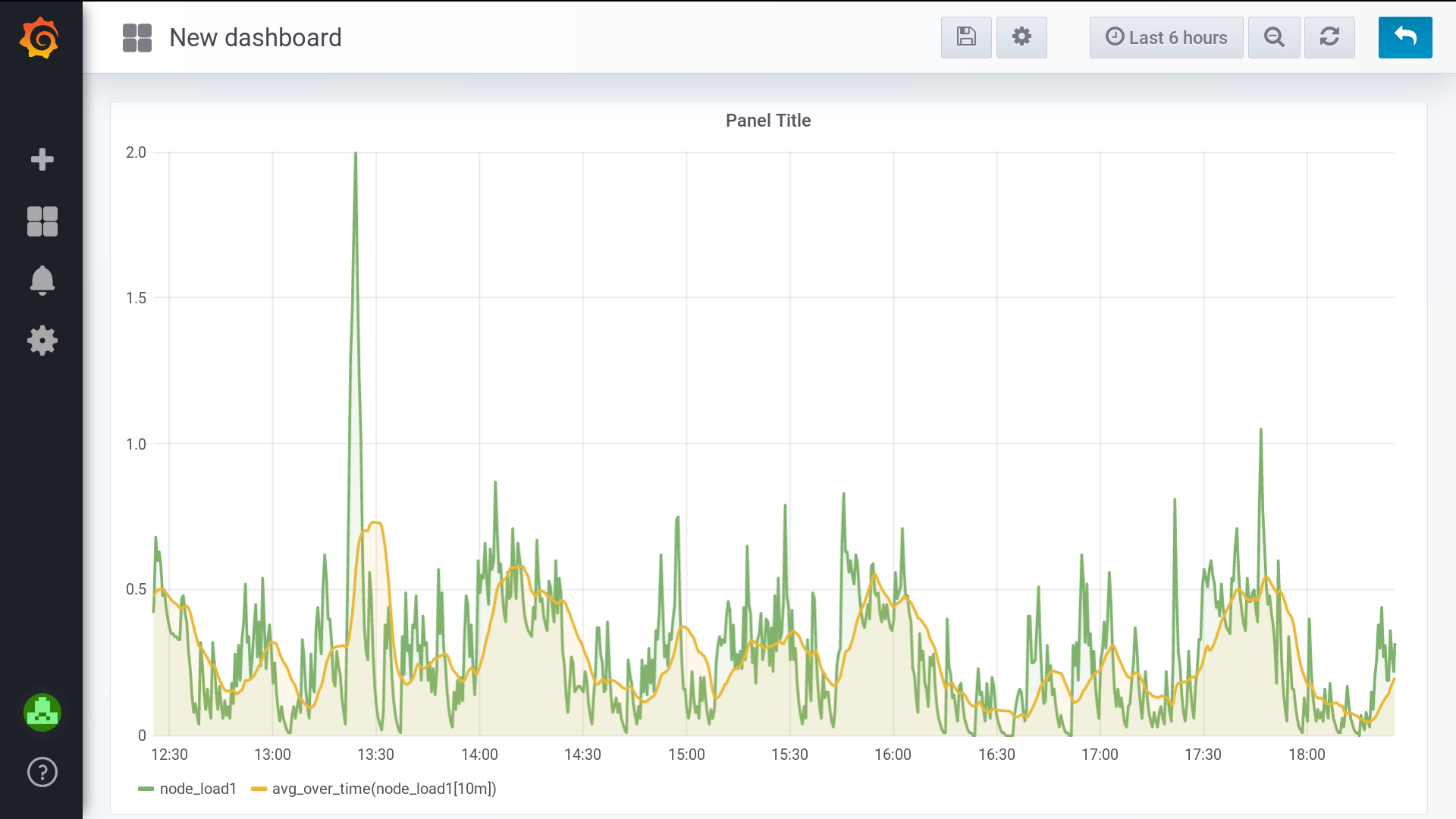
Оранжевый получен из зелёного усреднением за 10 минут. Да, это был мой любимый load average:
Expression: avg_over_time(node_load1{instance='localhost:9100'}[10m])
{instance="localhost:9100",job="node"} 0.23
Собственно, диапазонный вектор — это когда мы дописываем временной интервал в квадратных скобочках. Интервал времени для диапазонного вектора указывается очень по-человечески: 1s — одна секунда, 1m — одна минута, 1h — один час, 1d — день. А что, если нужно указать полтора часа? Просто напишите 90m.
Домашнее задание: посмотрите на графики max_over_time и min_over_time.
Типы метрик
Метрики бывают разных типов. Это важно, потому что для разных типов метрик применимы те или иные запросы.
Шкала (gauge). Самый простой тип метрик. Примеры: количество свободной/занятой ОЗУ, load average и т.д.
Счётчик (counter). Похож на шкалу, но предназначен совершенно для других данных. Счётчик может только увеличиваться, поэтому он подходит только для тех метрик, которые по своей природе могут только увеличиваться. Примеры: время работы CPU в определённом режиме (user, system, iowait…), количество запросов к веб-серверу, количество отправленных/принятых сетевых пакетов, количество ошибок. На практике вас не будет интересовать абсолютное значение счётчика, вас будет интересовать первая производная по времени, т.е. скорость роста этого счётчика, например количество запросов в минуту или количество ошибок за день.
Гистограмма (histogram). Я пока не сталкивался с таким типом, поэтому ничего путного не скажу.
Саммари (summaries). Что-то похожее на гистограммы, но другое.
Смотрим счётчики
Посмотрим счётчики на примере сетевого трафика:
Expression: node_network_receive_bytes_total{instance='localhost:9100'}
node_network_receive_bytes_total{device="br-03bbefe4ab97",instance="localhost:9100",job="node"} 0
node_network_receive_bytes_total{device="docker0",instance="localhost:9100",job="node"} 0
node_network_receive_bytes_total{device="lo",instance="localhost:9100",job="node"} 16121707
node_network_receive_bytes_total{device="vethab0ac76",instance="localhost:9100",job="node"} 0
node_network_receive_bytes_total{device="vethd3da657",instance="localhost:9100",job="node"} 0
node_network_receive_bytes_total{device="wlp3s0",instance="localhost:9100",job="node"} 4442690377
Сырое значение счётчика не несёт никакого смысла, его надо оборачивать функцией rate или irate. Эти функции принимают на вход диапазонный вектор, поэтому правильный запрос выглядит так:
Expression: rate(node_network_receive_bytes_total{device="wlp3s0"}[5m])
node_network_receive_bytes_total{device="wlp3s0",instance="localhost:9100",job="node"} 1210.6877192982456
Expression: irate(node_network_receive_bytes_total{device="wlp3s0"}[5m])
node_network_receive_bytes_total{device="wlp3s0",instance="localhost:9100",job="node"} 1210.6877192982456
В чём разница между rate и irate? Первая функция для вычисления производной берёт весь диапазон (5 минут в нашем случае), а вторая берёт лишь два последних сэмпла из всего диапазона, чтобы максимально приблизиться к мгновенному значению (первоисточник). Собственно, её название расшифровывается как instant rate.
Почему мы берём диапазонный вектор за 5 минут, а не за 1 или 10? Не знаю. Почему-то так делают во всех примерах и в дашборде Node exporter full тоже так. Для rate получается, что чем меньше интервал, тем больше пиков, а чем больше интервал, тем сильнее их сглаживание. Ну, с математикой не поспоришь. Для irate величина диапазона не имеет значения. На самом деле при определённых обстоятельствах всё-таки имеет, но это настолько тонкий нюанс, что на него можно забить.
Другой вопрос: 1210 — это в каких попугаях? Во-первых смотрим исходную метрику, там явно написано bytes. Функция rate делит исходную размерность на секунды, получается байт в секунду. Вообще Prometheus предпочитает стандартные единицы измерения: секунды, метры, ньютоны и т.п. Как в школе на уроках физики.
Считаем загрузку процессора
С памятью, диском и трафиком понятно, а как посмотреть загрузку процессора? Отвечаю. То, что мы привыкли считать загрузкой процессора в процентах на самом деле вот какая штука: сколько времени (в процентном отношении) процессор не отдыхал, т.е. не находился в режиме idle.
Итак, всё начинается с метрики node_cpu_seconds_total. Сначала посмотрим сколько времени процессор отдыхал:
Expression: irate(node_cpu_seconds_total{mode="idle"}[5m])
{cpu="0",instance="anotherhost:9100",job="node",mode="idle"} 0.5654385964909013
{cpu="0",instance="localhost:9100",job="node",mode="idle"} 0.9553684210526338
{cpu="1",instance="anotherhost:9100",job="node",mode="idle"} 0.5772631578931683
{cpu="1",instance="localhost:9100",job="node",mode="idle"} 0.9684912280701705
{cpu="2",instance="localhost:9100",job="node",mode="idle"} 0.9665614035087696
{cpu="3",instance="localhost:9100",job="node",mode="idle"} 0.9668421052631616
Возьмём среднее значение по ядрам и переведём в проценты:
Expression: avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) without (cpu) * 100
{instance="anotherhost:9100",job="node",mode="idle"} 49.67368421054918
{instance="localhost:9100",job="node",mode="idle"} 96.87368421052636
Ну и наконец получим загрузку процессора:
Expression: 100 - avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) without (cpu) * 100
{instance="anotherhost:9100",job="node",mode="idle"} 49.21052631578948
{instance="localhost:9100",job="node",mode="idle"} 3.458771929824593
Любопытно, что сумма всех режимов работы процессора никогда не доходит до 100% времени:
Expression: sum (irate(node_cpu_seconds_total[5m])) without (mode)
{cpu="0",instance="anotherhost:9100",job="node"} 0.9739999999999347
{cpu="0",instance="localhost:9100",job="node"} 0.9991578947368495
{cpu="1",instance="anotherhost:9100",job="node"} 0.9083157894731189
{cpu="1",instance="localhost:9100",job="node"} 0.9985964912280734
{cpu="2",instance="localhost:9100",job="node"} 0.998456140350873
{cpu="3",instance="localhost:9100",job="node"} 0.9983508771929828
Почему так? Хороший вопрос. Я подозреваю, что оставшаяся часть времени уходит на переключение контекста процессора. Получается, что загрузка процессора, полученная по формуле выше, будет чуть-чуть завышенной. В действительности можно не переживать по этому поводу, потому что погрешность получается незначительная. Это просто у меня anotherhost работает на старом процессоре Intel Atom. На нормальных взрослых процессорах погрешность не превышает десятые доли процента.
И это всё?
Думаю, на сегодня достаточно. Да, я рассказал не про все возможности PromQL. Например, за кадром остались операторы ignoring и on, логические and и or а также сдвиг offset. Есть всякие интересности типа производной по времени deriv или предсказателя будущего predict_linear. При желании вы сможете почитать про них в документации: операторы и функции. Я же вернусь к ним, когда мы будем решать практические задачи мониторинга.